ensemble model 殺器:staking 堆疊模型
stacking 是集成(ensemble)模型的方法,也可以視為提取特徵的方式。主要是為了降低方差(variance),但多層的情況下也能降低偏差(deviation)。
堆疊模型的方法在資料競賽平台 Kaggle 中時常是贏得比賽的策略,堆疊模型的概念是通過多個模型使用 out- of-fold的方方式來訓練便將預測值視為新特徵,這個方式可以強化每個 model 的弱點,簡單來說利用不同演算法從不同的數據空間角度和數據結構角度的對數據的不同觀測,來取長補短,優化結果。因此會建議用原理或計算方式較為不同的 model 來做為訓練 model。
這些模型我們稱為 meta learner,產生出來的特徵則稱為 meta feature
舉個例子,KNN 是透過距離的遠近來分類,決策數則是透過 entropy 或 Gini 不純度來分裂節點,並找出分類規則,而 Random Forest 則是透過 bagging 後投票來做出預測,因使不同觀點的模型和演算法,都有不一樣的優缺點,故使用 stacking 就是將各個模型的優缺點截長補短。
步驟一 | 建立 base learner
首先先導入 data, 並將 data 分為 train & test,因為要使用 out-of-fold 來堆疊不同的模型,故須將 train data 再分為 train data 和 valid data
這邊是用乳癌的資料來做示範
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import log_loss
from sklearn.model_selection import KFold
import numpy as np
import pandas as pd
import os
# 載入乳癌資料集
breast_cancer = load_breast_cancer()
train_x, test_x, train_y, test_y = train_test_split(
breast_cancer.data, breast_cancer.target, test_size = 0.2, random_state = 0)
train_x = pd.DataFrame(train_x, columns=['feature_{}'.format(i) for i in range(train_x.shape[1])])
train_y = pd.Series(train_y)
test_x = pd.DataFrame(test_x, columns=['feature_{}'.format(i) for i in range(test_x.shape[1])])
先各自定義第一層模型,第一層模型盡量使用不同原理的 model 來堆疊,故這邊分別使用 tree-baesd 並使用 begging 投票方式的 Random Forest,使用高維空間的平面並尋找邊界最大化的 SVM,以及 GBDT 家族中的 XGBoost
這邊稍微說明一下,因為 sklearn 中模型計算是使用 numpy array,故 array 中在訓練模型是不能有 NA 值的,不然一般來說 tree-based 的 model,例如 Random Forest 是不需要填補 NA 值的
這邊的 parms 並沒有特別優化,只是依照一般會使用的大略值來計算
# SVM
class SVM:
def __init__(self):
self.model = None
self.scaler = None
self.imputer = None
def fit(self, tr_x, tr_y, va_x, va_y):
self.imputer = SimpleImputer(strategy = 'mean')
tr_x = self.imputer.fit_transform(tr_x)
self.scaler = StandardScaler()
self.scaler.fit(tr_x)
tr_x = self.scaler.transform(tr_x)
self.model = SVC(C = 1.0, kernel = 'rbf', gamma ='auto', probability = True)
self.model.fit(tr_x, tr_y)
def predict(self, x):
x = self.imputer.transform(x)
x = self.scaler.transform(x)
pred = self.model.predict_proba(x)[:, 1]
return pred
# Random Forest
class RandomForest:
def __init__(self):
self.model = None
self.scaler = StandardScaler()
self.imputer = SimpleImputer(strategy = 'mean')
def fit(self, tr_x, tr_y, va_x, va_y):
tr_x = self.imputer.fit_transform(tr_x)
params = {'criterion': 'entropy', 'max_depth': 5, 'random_state': 71}
n_estimators = 100
self.scaler.fit(tr_x)
tr_x = self.scaler.transform(tr_x)
self.model = RandomForestClassifier(n_estimators = n_estimators, **params)
self.model.fit(tr_x, tr_y)
def predict(self, x):
x = self.imputer.transform(x)
x = self.scaler.transform(x)
pred = self.model.predict_proba(x)[:, 1]
return pred
# XGBoost
class Model1Xgb:
def __init__(self):
self.model = None
def fit(self, tr_x, tr_y, va_x, va_y):
params = {'objective': 'binary:logistic', 'silent': 1, 'random_state': 71,
'eval_metric': 'logloss'}
num_round = 20
dtrain = xgb.DMatrix(tr_x, label=tr_y)
dvalid = xgb.DMatrix(va_x, label=va_y)
watchlist = [(dtrain, 'train'), (dvalid, 'eval')]
self.model = xgb.train(params, dtrain, num_round, evals = watchlist)
def predict(self, x):
data = xgb.DMatrix(x)
pred = self.model.predict(data)
return pred
再來是定義 stacking 的架構,其實目前是有 stcking 的套件來直接幫忙做 stacking 堆疊,但 stacing 堆疊的方式較為複雜,透過自訂義來幫助了解整個流程是滿有幫助的。
def predict_cv(model, train_x, train_y, test_x):
preds = []
preds_test = []
va_idxes = []
x = []
kf = KFold(n_splits = 4, shuffle = True, random_state = 71)
# 在交叉驗證中進行訓練/預測,並保存預測值及索引
for i, (tr_idx, va_idx) in enumerate(kf.split(train_x)):
tr_x, va_x = train_x.iloc[tr_idx], train_x.iloc[va_idx] # kfold 產生訓練集和驗證集
tr_y, va_y = train_y.iloc[tr_idx], train_y.iloc[va_idx]
model.fit(tr_x, tr_y, va_x, va_y)
pred = model.predict(va_x)
preds.append(pred)
pred_test = model.predict(test_x)
preds_test.append(pred_test)
va_idxes.append(va_idx)
# 將驗證資料的預測值整合起來,並依序排列
va_idxes = np.concatenate(va_idxes)
preds = np.concatenate(preds, axis=0)
order = np.argsort(va_idxes)
pred_train = preds[order]
# 取測試資料的預測值平均
preds_test = np.mean(preds_test, axis=0)
return pred_train, preds_test
可以從程式碼中來一窺整個 stacking 的運作架構,這裡將 base learner 分為幾個流程的步驟來看。
- 分割資料集為訓練集和測試集
- 定義 base leaner 需要的 model
- 使用
k-fold 交叉驗證來訓練基本模型
1 和 2 上面已經完成了,比較複雜的就是透過 k-fold 來訓練模型,可以從下圖來看一下整個 stakcing 的架構。
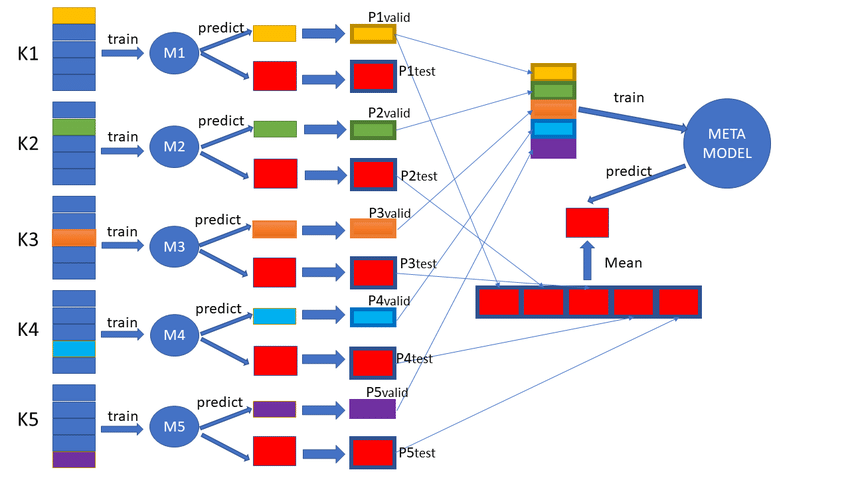
看起來非常的複雜,但我們可以一一的來拆解,我們的 base leaner 用三個模型來建構,分別為 SVM、XGBoost、randomforst。三個一起看有點複雜,那先拆解為其中一個模型的訓練過程如下
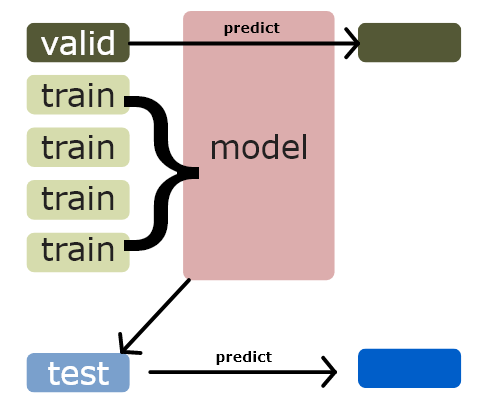
假設我們其中一個 model SVM 開始訓練,依圖來看,就是先將 train data 分成 n 折,因此每一折的 data row 的數量就都是 1/n,而第一次訓練用其他折來做訓練資料。
train data 此時分為 train data 和 validate data
train 完後的 model 在對 validate data 做 predict 此時就產生了 1/n 行的預測資料,這就是我們的新特徵。
而同時訓練完的資料也對 test data 做 predict ,當然也產生了新的預測資料
重複 K 次(k-fold 幾折就幾次)
然後就會產生如下圖的結果,假設我們分為 5 折,那每訓練一次就會產生 1/5 行原始 train data 的資料,最後分別折完 5 次和訓練 5 次後,就產生了和原始 train data 行數的資料特徵。
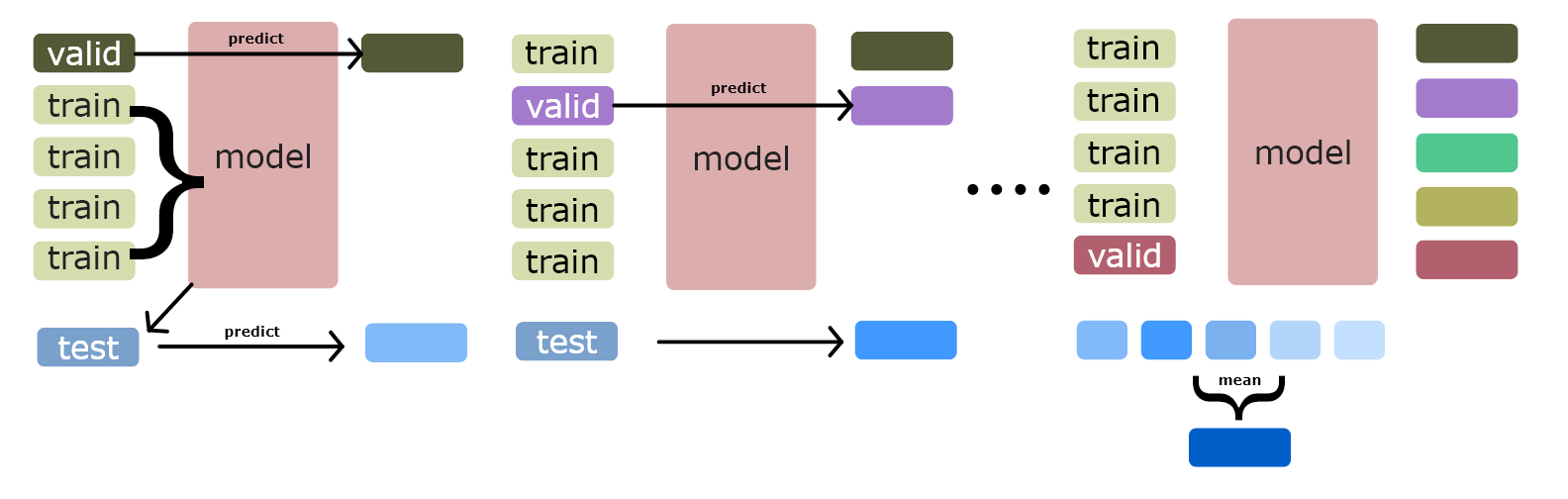
test data 同時每次訓練也都有產生新的 prediction,因此最後會將 test data 的 prediction 取平均後產生新的 test data
不一定要用平均,可以用其他方處理
因此最後會產生出和原有 train data 一樣行數,但列數為 model 數量的 data frame,這些就是新的第二層 feature,而接著 meta model 就要登場了
這裡的 test data 可以想像為對其做 stacking 的 transform
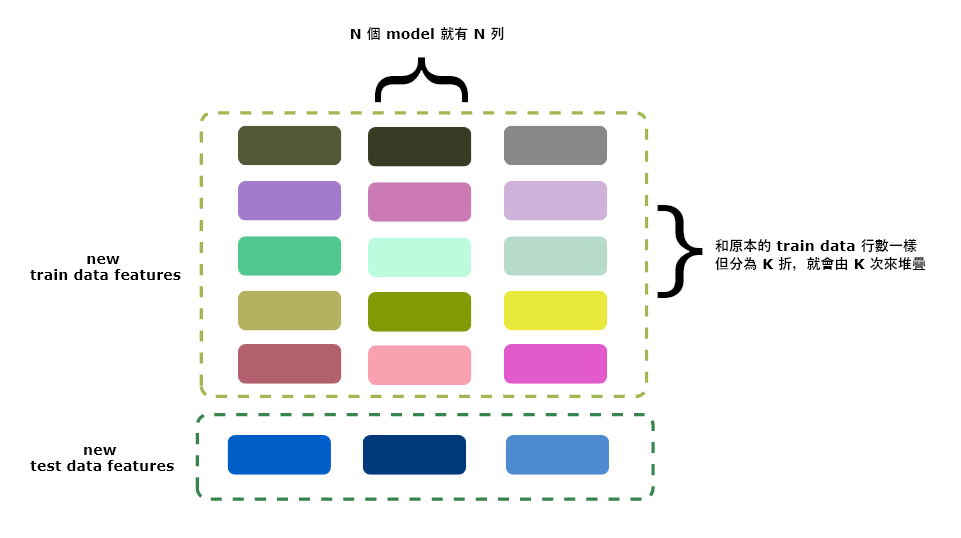
步驟二 | 訓練 meta model
一般來說 stcking model 很容易就過擬合,因此在最後一層產生最終資料結果的 model 都不會使用太複雜的模型,一般可以推薦縣性模型相關,這邊就是使用 logistic model
# 建立線性模型
class Model2Linear:
def __init__(self):
self.model = None
self.scaler = None
def fit(self, tr_x, tr_y, va_x, va_y):
self.scaler = StandardScaler()
self.scaler.fit(tr_x)
tr_x = self.scaler.transform(tr_x)
self.model = LogisticRegression(solver='lbfgs', C=1.0)
self.model.fit(tr_x, tr_y)
def predict(self, x):
x = self.scaler.transform(x)
pred = self.model.predict_proba(x)[:, 1]
return pred
最後一步就是訓練 meta model,而 meta model 就是拿新產生的特徵值當作 X, 然後原本 train data 的 label 值拿來當 y 來訓練 meta model。
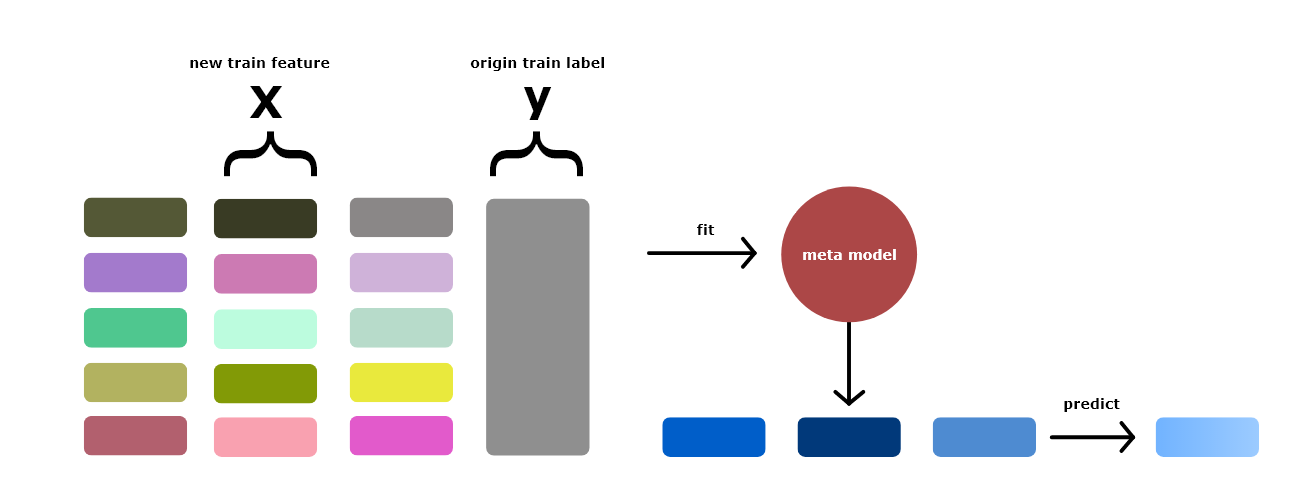
這時候可以考慮加上原有的特徵加入訓練,不過這樣比較容易過擬合,或是將原有的特徵做降維後再加入訓練。
test data 可以透過多折後預測的的平均來預測 test data,也可以將在折後產生 train data 的新特徵後,重新用全部的 train data 對 model 做 training 然後在對 test data 做出預測。
在第二層有一些小變化可以調整,不過重要的是需要來自上一層的模型在未知標籤下去做出預測。
以下就是針對各個 base leaner 中的 model 做 predict
# 使用 XGBoost
import xgboost as xgb
model_1a = Model1Xgb()
pred_train_1a, pred_test_1a = predict_cv(model_1a, train_x, train_y, test_x)
# 使用 SVM
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
model_1b = SVM()
pred_train_1b, pred_test_1b = predict_cv(model_1b, train_x, train_y, test_x)
# 使用 RandomForest
from sklearn.ensemble import RandomForestClassifier
model_1c = RandomForest()
pred_train_1c, pred_test_1c = predict_cv(model_1c, train_x, train_y, test_x)
然後將各個 base model 計算出的結果對比 train data 的 y 看 logloss 的效果,不過這是在 train data 上的評價,不代表真正對於未知 data 的預測狀況
print('logloss: {:.4f}'.format(log_loss(train_y, pred_train_1a, eps = 1e-7)))
print('logloss: {:.4f}'.format(log_loss(train_y, pred_train_1b, eps = 1e-7)))
print('logloss: {:.4f}'.format(log_loss(train_y, pred_train_1c, eps = 1e-7)))
可以看到結果,意外的竟然是 SVM 效果最好
logloss: 0.1553
logloss: 0.0989
logloss: 0.1195
接著我們要來訓練 meta model,首先先將新的特徵值合併
# 將預測值作為特徵並建立 dataframe
train_x_2 = pd.DataFrame({'pred_1a': pred_train_1a, 'pred_1b': pred_train_1b, 'pred_1c': pred_train_1c})
test_x_2 = pd.DataFrame({'pred_1a': pred_test_1a, 'pred_1b': pred_test_1b, 'pred_1c': pred_test_1c})
然後定義 logistic model
# 建立線性模型
class Model2Linear:
def __init__(self):
self.model = None
self.scaler = None
def fit(self, tr_x, tr_y, va_x, va_y):
self.scaler = StandardScaler()
self.scaler.fit(tr_x)
tr_x = self.scaler.transform(tr_x)
self.model = LogisticRegression(solver='lbfgs', C=1.0)
self.model.fit(tr_x, tr_y)
def predict(self, x):
x = self.scaler.transform(x)
pred = self.model.predict_proba(x)[:, 1]
return pred
最後 fit 以 meta model 來 fit 新的特徵值,這邊因為已經定義了 predict_cv 的方法,故仍用 oof 來訓練,不過第二層可以直接訓練不用一定要使用折外
model_2 = Model2Linear()
pred_train_2, pred_test_2 = predict_cv(model_2, train_x_2, train_y, test_x_2)
print(f'logloss: {log_loss(train_y, pred_train_2, eps=1e-7):.4f}')
最後看一下其 logloss,可以看出相較於 3 各 base-model 其 logloss 又再下降惹。
logloss: 0.0898
試著使用 chatGPT 寫程式
因為在理解 stacking 的過程中,網路上資料不多,Kaggle 上的教學有些 code 真的太複雜看不太懂,花滿多時間才真的了解其架構,後來有使用 chatGPT 來做一些詢問,在交談和修正的過程,也透過 chatGPT 完成一段算是完整的 stacking flow code,我們可以看一下,透過 chatGPT 寫出來的程式和我們原本的有啥差異。這邊同樣都是用乳癌資料來建立 stacking flow。
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score
import numpy as np
# 載入乳癌資料集
breast_cancer = load_breast_cancer()
# 分割資料集為訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(
breast_cancer.data, breast_cancer.target, test_size=0.2, random_state=0)
這邊比較簡單的建立 base model 和 meta model,甚至沒有啥做超參數設定,不過如過進一步細緻的去要求 chatGPT 其實他會完成的更完整。🙄
# 定義基本模型
base_models = [
RandomForestClassifier(n_estimators = 100, random_state = 0),
XGBClassifier(n_estimators = 100, random_state = 0),
SVC(random_state = 0)
]
# 定義 meta-model
meta_model = LogisticRegression(random_state = 0)
# 定義交叉驗證的 fold 數量
n_folds = 5
# 初始化 arrays,用來保存基本模型和 meta-model 的訓練和測試預測結果
base_model_train_pred = np.zeros((X_train.shape[0], len(base_models)))
base_model_test_pred = np.zeros((X_test.shape[0], len(base_models)))
使用 oof 來建立 new features
kf = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=0)
for i, model in enumerate(base_models):
for train_idx, valid_idx in kf.split(X_train, y_train):
X_train_fold, y_train_fold = X_train[train_idx], y_train[train_idx]
X_valid_fold, y_valid_fold = X_train[valid_idx], y_train[valid_idx]
model.fit(X_train_fold, y_train_fold)
base_model_train_pred[valid_idx, i] = model.predict_proba(X_valid_fold)[:, 1]
base_model_test_pred[:, i] += model.predict_proba(X_test)[:, 1] / n_folds
訓練 meta model 並做出預測,這邊看的出來其再對 meta model 做訓練時沒有用 k-fold,而是直接去 fit 整個 new data feautures,個人覺得差異性不大,因為針對 new data features 都是在未知標籤下去做預測,如果需要再疊一層則才一定需要做 k-fold。
# 使用基本模型的預測結果訓練 meta-model
meta_model.fit(base_model_train_pred, y_train)
# 使用 meta-model 預測測試集
pred = meta_model.predict_proba(base_model_test_pred)[:, 1]
logloss = log_loss(y_test, pred)
print('logloss: {:.4f}'.format(logloss))
效果也是滿不錯的 🤒
logloss: 0.0859
新的資料近來如何使用 stacking
如果是 kaggle 的比賽,那直接對 test data 做預測就好,由於 stacking 架構較複雜,那實務上要怎麼使用呢?
- 先將訓練好的 model 儲存成 pickle 檔,這樣下次要預測時可以呼叫出來不用再重新訓練。
實務上這種概念就像是我們一般在電腦上將檔案存成 zip 或 rar 然後要使用時解壓縮一樣,因此任何程式的物件都能一樣的操作,這種方式就很像在 Spark 上將物件存成 parquet
- 呼叫訓練好的 base model 預測新的 features
# 假設有一筆新的資料 new_data,shape 為 (1, 30)
new_data = np.random.rand(10, 30)
# 使用已訓練好的 base models 預測 new_data
base_model_pred = np.zeros((10, len(base_models)))
for i, model in enumerate(base_models):
base_model_pred[:, i] = model.predict_proba(new_data)[:, 1]
- 使用已訓練好的 meta model 預測 new_data
meta_model_pred = meta_model.predict_proba(base_model_pred)[:, 1]
print(meta_model_pred)
[0.91237343 0.83224565 0.85927932 0.95671311 0.82796747 0.95660662
0.86298109 0.81283893 0.84073246 0.85952858]
不過像是乳癌這種資料還有型一錯誤的這種狀況,故其在算機率做預測時,需要再額外調整閥值(threshold),不過這是另外的課題,整個 stacking 的架構大概是這樣,不過一般實務上不太需要使用這麼複雜的架構,一般假設是行銷或分類可能用單一的 GBDT 就能解決了。
因為 stacking 的架構需要比較大量的計算資源,假設有 k 折,N 個 model 就需要計算 k*N 次的訓練,因此當資料量很大時並不一定適合用在實務上。
Referance
A Deep Dive into Stacking Ensemble Machine Learning — Part I
A Deep Dive into Stacking Ensemble Machine Learning — Part II
5.4 Stacking【斯坦福21秋季:实用机器学习中文版】